混沌工程
运维部大佬推广故障演练,也介绍了混沌工程的概念。正好最近在搜集故障注入资料时也看到了 ChaosBlade,搬运一些资料扫个盲
1. 什么是混沌工程(Chaos Engineering)
混沌工程是一门在系统上进行实验的学科,其目的是为了建立对大规模分布式系统能力的信心,使其能够在生产环境中弹性应对各种突发性故障。
在整个分布式系统中,即使每一个单体服务运转良好,服务与服务之间的通信和交互也会带来不可预测的结果,再加上现实世界中一些罕见但破坏性极强的事件(比如机房突然断电、地震等),导致整个分布式系统在本质上混乱的。我们需要一套能够在分布式系统出现异常问题前发现这些系统弱点的方法论,这些系统性弱点包括:
- 系统故障时不可用的降级方案
- 不合理的超时时间
- 依赖的第三方服务发生突发性故障
- 单点故障后引发的级联故障
- ......
即使我们能够针对这些问题做足相应的预案(很多情况下其实并不能),配合监控报警、流控降级等应对措施,但这些都是被动的保障手段。对于这些核心的系统性弱点,我们能否在真正发生前就能够识别和改善?并能够建立一套高度抽象化的方法论和实践原则,来管理、发现、改善这些复杂分布式系统中固有的混乱,提高分布式系统的稳定性,并提高我们对于系统的信心。
混沌工程的出现就是为了解决以上问题。通过在系统上建立可控制的实验,来观察和了解分布式系统中的各种行为和表现。
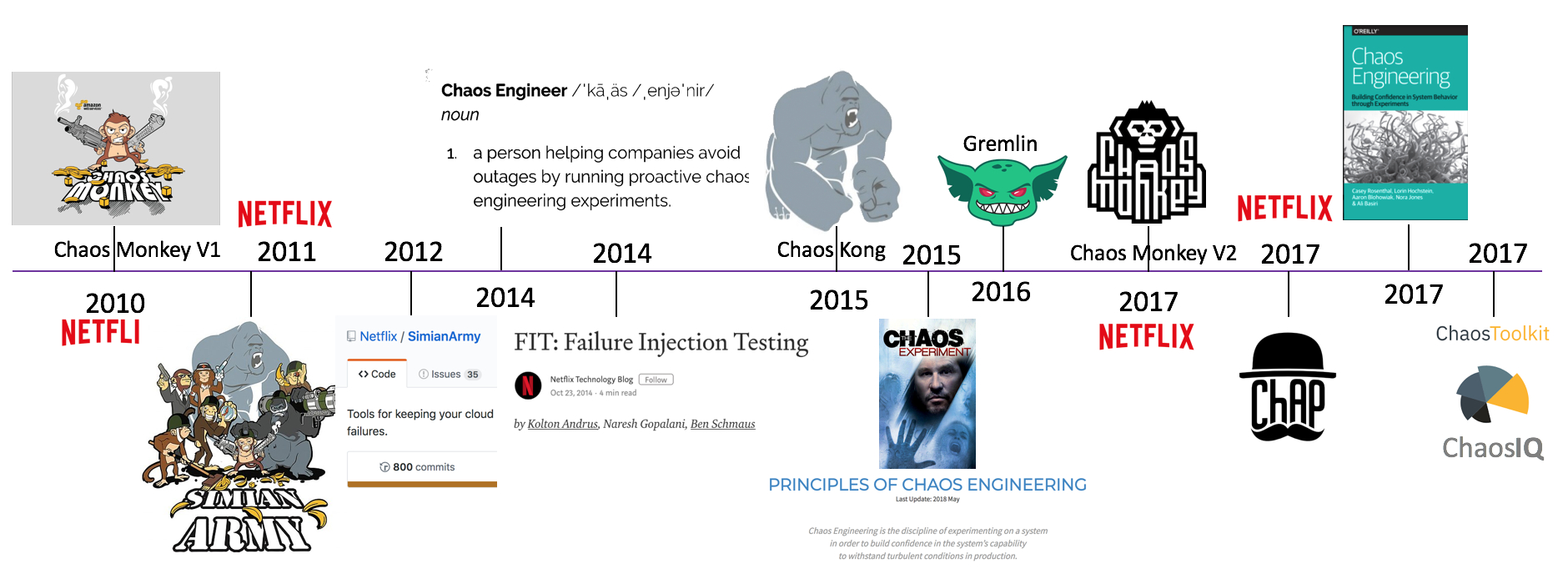
2. 混沌工程发展历程
Copy From https://aws.amazon.com/cn/blogs/china/aws-chaos-engineering-start/
2008 年 8 月, Netflix 主要数据库的故障导致了三天的停机, DVD 租赁业务中断,多个国家的大量用户受此影响。之后 Netflix 工程师着手寻找替代架构,并在 2011 年起,逐步将系统迁移到 AWS 上,运行基于微服务的新型分布式架构。这种架构消除了单点故障,但也引入了新的复杂性类型,需要更加可靠和容错的系统。为此, Netflix 工程师创建了 Chaos Monkey ,会随机终止在生产环境中运行的 EC2 实例。工程师可以快速了解他们正在构建的服务是否健壮,有足够的弹性,可以容忍计划外的故障。至此,混沌工程开始兴起。
- 2010 年 Netflix 内部开发了 AWS 云上随机终止 EC2 实例的混沌实验工具: Chaos Monkey
- 2011 年 Netflix 释出了其猴子军团工具集: Simian Army
- 2012 年 Netflix 向社区开源由 Java 构建 Simian Army,其中包括 Chaos Monkey V1 版本
- 2014 年 Netflix 开始正式公开招聘 Chaos Engineer
- 2014 年 Netflix 提出了故障注入测试(FIT),利用微服务架构的特性,控制混沌实验的爆炸半径
- 2015 年 Netflix 释出 Chaos Kong ,模拟 AWS 区域(Region)中断的场景
- 2015 年 Netflix 和社区正式提出混沌工程的指导思想 – Principles of Chaos Engineering
- 2016 年 Kolton Andrus(前 Netflix 和 Amazon Chaos Engineer )创立了 Gremlin ,正式将混沌实验工具商用化
- 2017 年 Netflix 开源 Chaos Monkey 由 Golang 重构的 V2 版本,必须集成 CD 工具 Spinnaker 来使用
- 2017 年 Netflix 释出 ChAP (混沌实验自动平台),可视为应用故障注入测试(FIT)的加强版
- 2017 年 由 Netflix 前混沌工程师撰写的新书“混沌工程”在网上出版
- 2017 年 Russell Miles 创立了 ChaosIQ 公司,并开源了 chaostoolkit 混沌实验框架
3. 混沌工程实践原则
- **建立对系统稳定状态的假设。**关注系统的可量化指标,而非系统内部属性。在一段时期内对这些可量化系统指标的统计和聚合,构成了系统最终的稳定状态。系统整体吞吐量、错误率、性能指标等都可以作为整个稳定状态下的量化指标。 在实验过程中,通过对这些系统指标的观察,来观察和验证系统本身是否在正常工作。
- **用多样的现实世界事件做验证。**采取真实世界会发生的世界作为混沌实验的变量,并根据潜在的影响和发生频率确定这些事件的优先级。例如 Iaas 层故障(实例宕机、硬盘故障)、系统故障(响应超时、返回值异常)以及一些非故障事件(流量激增等),任何一个可能会打破系统稳定状态的因素都可以被当做混沌实验的变量。
- **在生产环境中实验。**系统对于各种因素变化的反应在不同环境下是不同的(不同环境下的服务状态、流量等)。为了保证实验系统的真实性,混沌工程强烈建议直接在生产环境中进行实验。
- **自动化实验持续运行。**手动执行实验本身是一件劳动密集型的工作,需要耗费大量的人力和时间,并且往往是不可持续的。 混沌工程需要一套能够自动化运行、观察、分析的方案对实验进行自动化实施。
- **最小爆炸半径。**在生产环境上实施实验可能会导致不必要的线上故障,且在一定程度上是不可避免的。但实施人员有责任和义务保证实验本身是可控制的,确保最小范围的影响。
4. 阿里巴巴混沌工程
参考资料:
4.1 发展历程

4.2 混沌实验模型
目前的混沌实验主要包含故障模拟,我们一般对故障的描述如下:
- 10.0.0.1 机器上挂载的 A 磁盘满造成了服务不可用
- 所有节点上的 B dubbo 服务因为执行缓慢造成上游 A dubbo 服务调用延迟,从而造成用户访问缓慢
- Kubernetes A 集群中 B 节点上 CPU 所有核使用率满载,造成 A 集群中的 Pod 调度异常
- Kubernetes C 集群中 D Pod 网络异常,造成 D 相关的 Service 访问异常
通过上述,我们可以使用以下句式来描述故障:因为某某机器(或集群中的资源,如 Node,Pod)上的哪个组件发生了什么故障,从而造成了相关影响。我们也可以通过下图来看故障描述拆分:
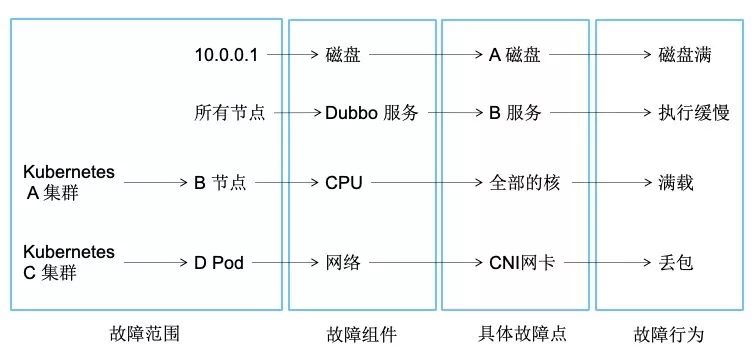
可以通过这四部分来描述现有的故障场景,所有我们抽象出了一个故障场景模型,也称为混沌实验模型
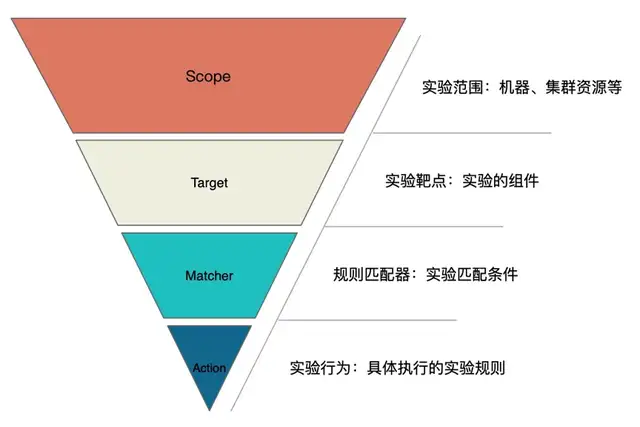
- Scope: 实验实施范围,指具体实施实验的机器、集群及其资源等
- Target: 实验靶点,指实验发生的组件。 如基础资源场景中的 CPU、网络、磁盘等,Java 场景中的应用组件如 Dubbo、Redis、RocketMQ、JVM 等,容器场景中的 Node、Pod、Container 自身等
- Matcher: 实验规则匹配器,根据所配置的 Target,定义相关的实验匹配规则,可以配置多个。 由于每个 Target 可能有各自特殊的匹配条件,比如 RPC 领域的 Dubbo、gRPC 可以根据服务提供者提供的服务和服务消费者调用的服务进行匹配,缓存领域的 Redis,可以根据 set、get 操作进行匹配。 还可以对 matcher 进行扩展,比如扩展实验场景执行策略,控制实验触发时间。
- Action: 指实验模拟的具体场景,Target 不同,实施的场景也不一样,比如磁盘,可以演练磁盘满,磁盘 IO 读写高,磁盘硬件故障等。 如果是应用,可以抽象出延迟、异常、返回指定值(错误码、大对象等)、参数篡改、重复调用等实验场景。 如果是容器服务,可以模拟 Node、Pod、Container 资源异常或者其上的基础资源异常等。
使用此模型可以很清晰表达出以下实施混沌实验需要明确的问题:
- 混沌实验的实施范围是什么
- 实施混沌实验的对象是什么
- 实验对象触发实验的条件有哪些
- 具体实施什么实验场景
4.3 混沌实验工具 - ChaosBlade
ChaosBlade 是一款遵循混沌实验模型,提供丰富的故障场景实现,帮助分布式系统提升容错性和可恢复性的混沌工程工具,特点是操作简洁、无侵入、扩展性强
github:https://github.com/chaosblade-io/chaosblade
5. 混沌工程与故障注入的区别
个人想法,不一定对
- 目标:故障注入是采用某种手段完成对一个具体异常场景的"验证测试",看看是否符合预期;混沌工程更多是做"探索性"的验证,不断延伸摸索系统的临界值(有点类似 KPI 和 OKR?)
- 发生阶段:故障注入多为测试环境,混沌工程偏重生产环境
- 故障类型:故障注入通常为 RPC/HTTP 请求超时、error 或者其他中间件的异常返回等;混沌工程除此之外还包含容器等更为严重的故障